
使用 PyCaret 进行多时间序列预测
使用 PyCaret 进行多时间序列预测
使用 PyCaret 进行多时间序列预测的逐步教程
PyCaret
PyCaret 是一个用 Python 构建的开源、低代码机器学习库和端到端模型管理工具,用于自动化机器学习工作流程。它因其易用性、简洁性以及快速高效地构建和部署端到端 ML 原型的能力而广受欢迎。
PyCaret 是一个替代性的低代码库,只需几行代码即可替代数百行代码。这使得实验周期呈指数级加快且高效。
PyCaret 简单且 易于使用。在 PyCaret 中执行的所有操作都按顺序存储在一个 Pipeline 中,该 Pipeline 完全自动化用于**部署**。无论是填充缺失值、独热编码、转换分类数据、特征工程,甚至是超参数调优,PyCaret 都能自动化完成。
本教程假定您对 PyCaret 有一定的先验知识和经验。如果您之前没有使用过,没关系 — 您可以通过这些教程快速入门
回顾
在我的上一教程中,我演示了如何使用 PyCaret 通过机器学习预测时间序列数据,通过PyCaret 回归模块。如果您还没有阅读过,您可以阅读使用 PyCaret 回归模块进行时间序列预测教程,然后再继续本教程,因为本教程建立在上一教程中涵盖的一些重要概念之上。
安装 PyCaret
安装 PyCaret 非常简单,只需几分钟。我们强烈建议使用虚拟环境,以避免与其他库发生潜在冲突。
PyCaret 的默认安装是 pycaret 的精简版本,只安装硬性依赖项,即此处列出.
当您安装 pycaret 的完整版本时,所有可选的依赖项,例如此处列出也都会安装。
👉 PyCaret 回归模块
PyCaret 回归模块是一个监督机器学习模块,用于估计因变量(通常称为“结果变量”或“目标”)与一个或多个自变量(通常称为“特征”或“预测因子”)之间的关系。
回归的目的是预测连续值,如销售额、数量、温度、客户数量等。PyCaret 中的所有模块都提供了许多预处理功能,通过setup函数准备数据进行建模。它拥有超过 25 个即用型算法和多种图表来分析训练模型的性能。
👉 数据集
在本教程中,我将展示多时间序列数据预测的端到端实现,包括训练和预测未来值。
我使用了商店商品需求预测挑战赛来自 Kaggle 的数据集。该数据集包含 10 个不同的商店,每个商店有 50 件商品,即总共 500 个为期五年(2013-2017 年)的日级别时间序列数据。

👉 加载并准备数据

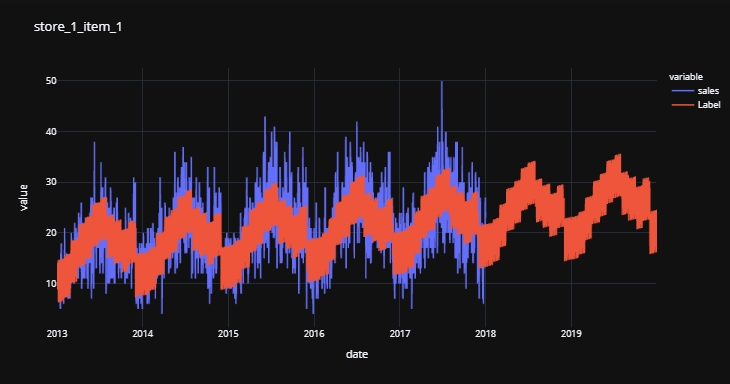
👉 可视化时间序列


👉 开始训练过程
现在数据已准备就绪,让我们开始训练循环。请注意,所有函数中都将 verbose = False,以避免在训练时在控制台上打印结果。
下面的代码是围绕我们在数据准备步骤中创建的 time_series 列的循环。总共有 150 个时间序列(10 家商店 x 50 件商品)。
下面的第 10 行是根据 time_series 变量过滤数据集。循环内的第一部分是初始化 setup 函数,然后是 compare_models 找到最佳模型。第 24-26 行捕获结果并将最佳模型的性能指标附加到一个名为 all_results 的列表中。代码的最后一部分使用 finalize_model 函数在包括测试集中剩余的 5% 的整个数据集上重新训练最佳模型,并将包括模型在内的整个 pipeline 保存为 pickle 文件。
现在我们可以从 all_results 列表中创建一个数据框。它将显示为每个时间序列选择的最佳模型。

训练过程 👇

👉 使用训练好的模型生成预测
现在我们已经训练好模型,让我们使用它们来生成预测,但首先,我们需要创建用于评分的数据集(X 变量)。

现在让我们创建一个循环来加载训练好的 pipeline 并使用 predict_model 函数生成预测标签。

我们现在将连接 data 和 concat_df。

我们现在可以创建一个循环来查看所有图表。


我希望您能体会到 PyCaret 的易用性和简洁性。仅用不到 50 行代码和一个小时的实验,我就训练了超过 10,000 个模型(25 个估计器 x 500 个时间序列),并将 500 个最佳模型投入生产以生成预测。
即将推出!
下周我将撰写一篇关于使用PyCaret 异常检测模块在时间序列数据上进行无监督异常检测的教程。请在Medium, LinkedIn和Twitter上关注我,获取更多更新。
使用这个轻量级的 Python 工作流程自动化库,您可以实现无限可能。如果您觉得这很有用,请不要忘记在我们的 GitHub 仓库上给我们点 ⭐️。
要了解更多关于 PyCaret 的信息,请关注我们的LinkedIn和Youtube.
加入我们的 slack 频道。邀请链接此处.
您可能也对以下内容感兴趣
使用 PyCaret 2.0 在 Power BI 中构建您自己的 AutoML 使用 Docker 在 Azure 上部署机器学习 Pipeline 在 Google Kubernetes Engine 上部署机器学习 Pipeline 在 AWS Fargate 上部署机器学习 Pipeline 构建并部署您的第一个机器学习 Web 应用 使用 AWS Fargate 无服务器部署 PyCaret 和 Streamlit 应用 使用 PyCaret 和 Streamlit 构建并部署机器学习 Web 应用 在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
文档 博客 GitHub StackOverflow 安装 PyCaretNotebook 教程为 PyCaret 贡献
想了解某个特定模块吗?
点击下面的链接查看文档和工作示例。
最后更新于
这有帮助吗?